Gemmaで業務効率化は可能か Google開発の大規模言語モデル

Googleは2024年2月に、Gemmaという大規模言語モデル(LLM)を公開しました。
Gemmaは2023年12月に発表されたGeminiと同じ技術を活用した軽量版のLLMでありながら、その能力は他のテキスト生成AIにも引けを取らないと公表されています。Gemmaをどのように業務効率改善に活かすか、そのヒントを紹介します。
この記事の目次
テキスト生成AIの新モデルGemma
Gemmaの紹介の前に、まずテキスト生成AIの仕組みについて軽く解説します。
テキスト生成AIでは、自然な言語でテキストを生成するための仕組みとしてLLMが利用されています。
LLMは、大量の文章から単語の出現頻度などを解析して、自然言語をコンピュータに学習させたものです。
例えば、ChatGPT-4はOpenAI社が開発したLLMを用いて、ユーザーが入力したテキストを解析し、それに沿った返答が行われます。
Gemmaとは?
GemmaはGoogleによって開発されたLLMであり、2023年12月にGoogleからリリースされたテキスト生成AIであるGeminiと同様の技術で開発されています。
そして2024年2月、このGemmaがオープンモデルとして公開されました。
Gemmaはラテン語で『宝石』を表す言葉であり、『双子』を意味するGeminiと語感は似ているものの異なる単語です。
Gemmaは、下記リンクの公式ページに詳細な解説がなされています。
GemmaはGoogle Cloud上でも実行でき、ノートパソコンからでも開発・利用が可能な軽量さに大きなメリットがあります。
テキスト生成AIの精度を示すパラメータ数が20億のものと70億のものの2パターンあります。
加えて、事前トレーニングされたものと、さらにインストラクションチューニングが行われている2パターンが用意されています。
これらによって、開発者のニーズに合わせたカスタマイズが可能です。
Gemmaの利用方法①簡単なチャットを使ってみる
簡単なチャットシステムでGemmaの生成AIの精度を試すなら、『Hugging Chat』を利用してみましょう。
Hugging Chatは、Hugging Face社が運営しているチャットAIサービスで、Gemmaをはじめとしたさまざまな言語モデルを利用できます。
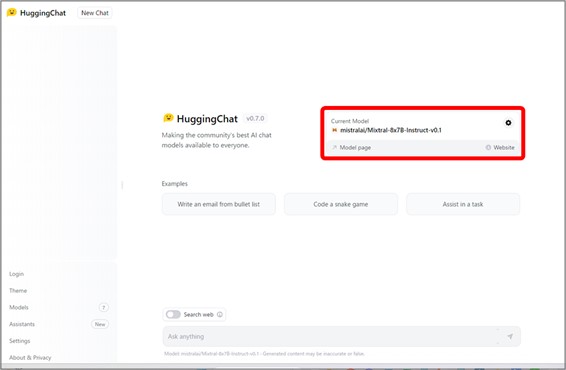
アクセスしたページの『Current Model』が『Google/gemma-7b-it』になっていない場合は、設定を変更します。
赤枠内右側の歯車マークをクリックして、遷移したページから『Google/gemma-7b-it』を選択し、『Activate』ボタンをクリックして確定させます。
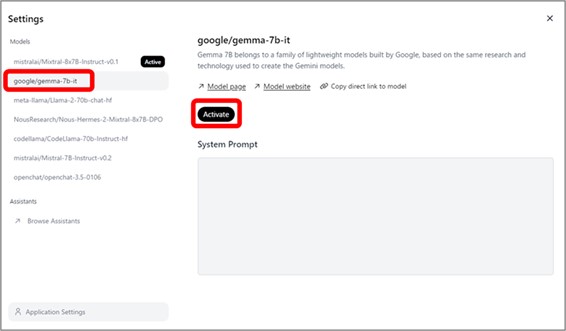
設定できたら、生成AIに返答してほしい内容を画面下にテキストを入力します。
日本語で入力すると、日本語で返答がありますが、GeminiやChatGPT-4などに比べると学習している数が少ないこともあり、抽象的な内容の質問にしてしまうと、誤った情報や日本語以外の言語が混ざることもあります。
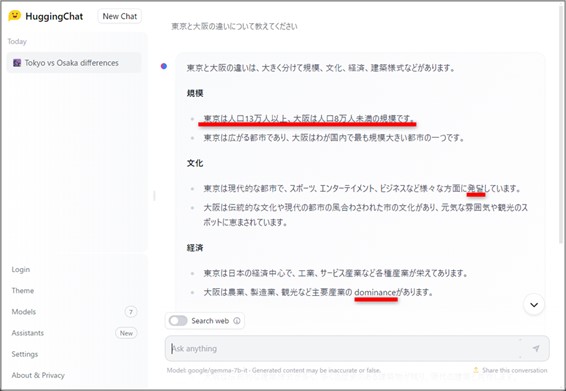
同じ内容を英語で質問すると、内容に一部の誤りはあるものの、日本語よりは正確な情報が返って来ます。
Gemmaの利用方法②Colabでプログラミングに利用する
Gemmaは、オンライン上でプログラミングのPythonを実行できるGoogle Colaboratory(Colab)とリンクできます。
これにより、Colab上でプログラムを作成する際に生成AIによるコードのアシスタントを直接利用できるようになります。
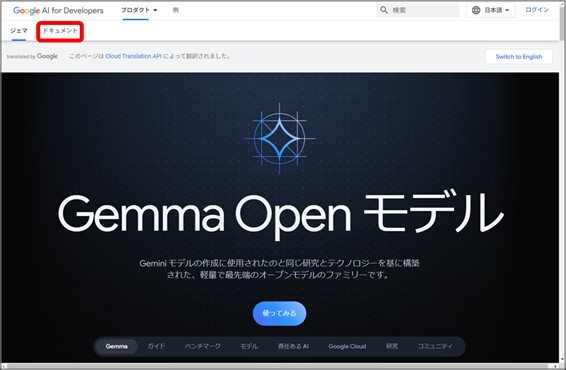
具体的なセットアップ方法は、画面左上の『ドキュメント』内にある『ガイド』>『Gemmaの設定』を確認します。
https://ai.google.dev/gemma/docs/setup?hl=ja
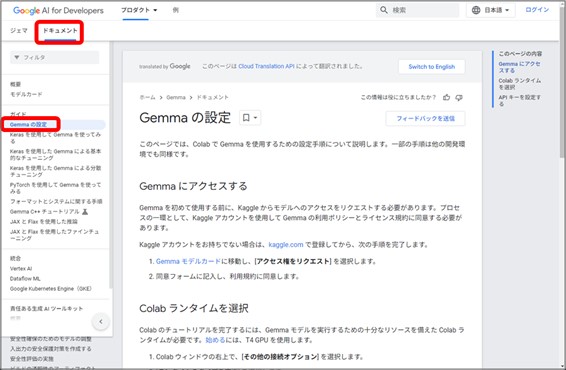
Gemmaの利用には、Kaggle というサイトのアカウントが必要です。
Kaggleは、企業や研究者がデータ分析や統計の最適なモデルを競い合うプラットフォームであり、Google傘下の企業です。
Kaggleのアカウントを持っていない場合は、サイトに移動してユーザー登録を行います。
Kaggleは日本語に対応していないため、英語でページを読むのが難しい場合は、Googleの拡張機能で翻訳をかけるなどして対応しましょう。
ユーザー登録は、画面右上の『Register』から可能です。GoogleアカウントかEメールアドレスでの登録となります。
指定するアカウントを決めて表示される名前を入力したら、プライバシーポリシーに同意することでアカウントが作成できます。
その後、Gemmaモデルカードのページに移動し、『Access Gemma on Kaggle』の項目の右にある『Request Access』をクリックします。
https://www.kaggle.com/models/google/gemma
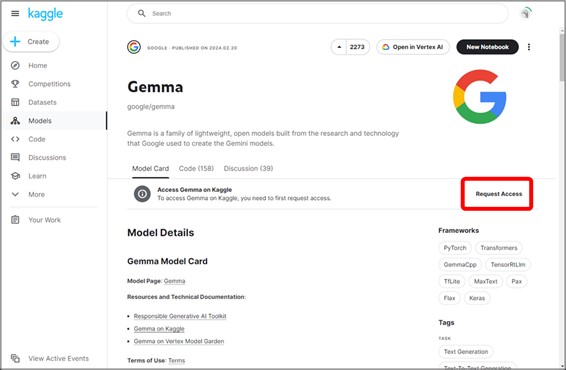
Request Accessをクリックすると、Gemmaへのアクセス権限を求めるページに遷移します。
利用規約に同意する場合は、最下部の2つのチェックボックスをクリックして、Acceptをクリックします。
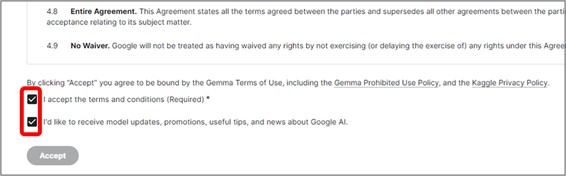
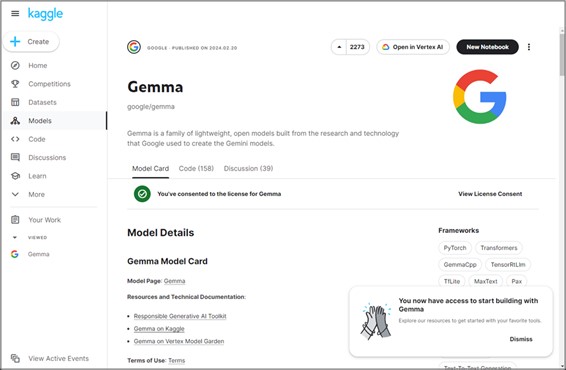
上記画面が現れたら、Gemmaへのアクセスが確保できた状態です。
次に、Colabランタイムの設定を行います。
Gemmaの公式ページ内『スタートガイド』にあるColabのリンクからアクセスするか、以下のURLをクリックしてください。
https://colab.research.google.com/github/google/generative-ai-docs/blob/main/site/en/gemma/docs/lora_tuning.ipynb
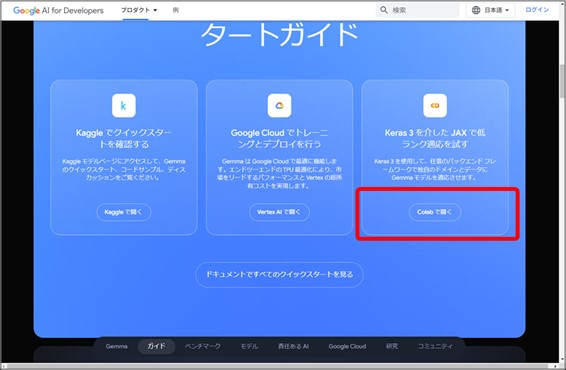
すると、下図のようなページに遷移します。
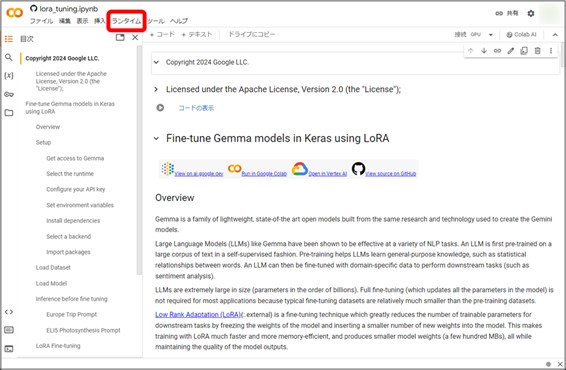
このページ内上部にある『ランタイム』から、『ランタイムのタイプを変更』を選択します。
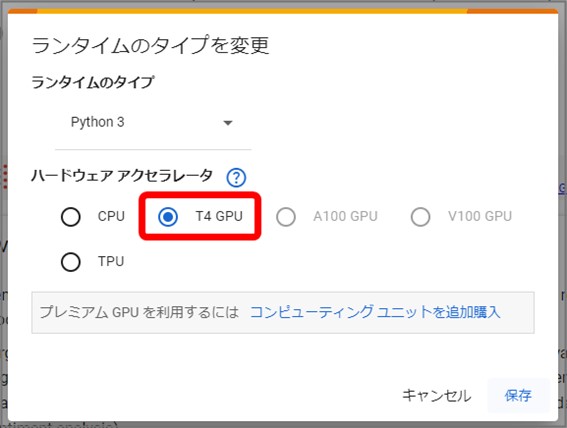
表示されたポップアップ内の『ハードウェアアクセラレータ』の項目を『T4 GPU』に変更して保存します。
最後に、Kaggle APIキーを生成して、Kaggleユーザー名と合わせて指定します。
Kaggleユーザープロフィールのページを表示します。
設定ページの中ほどにある『API』の項目から、『Create New Token』をクリックします。
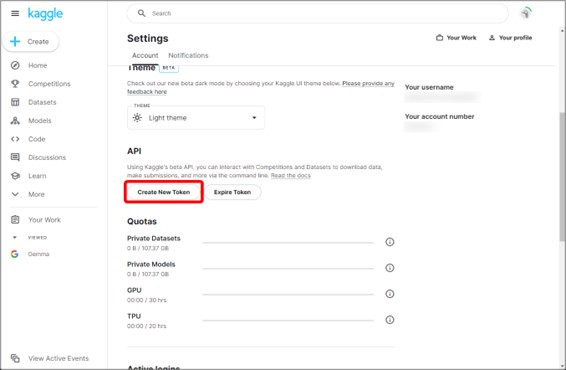
ここで、「kaggle.json」というファイルを保存します。このあとすぐにテキストエディタで中身を確認することになるので、分かりやすい場所に保存しましょう。
保存したjsonファイルを開くと、ユーザーネームとAPIキーがまとめて表記されているので、これをColabに登録します。
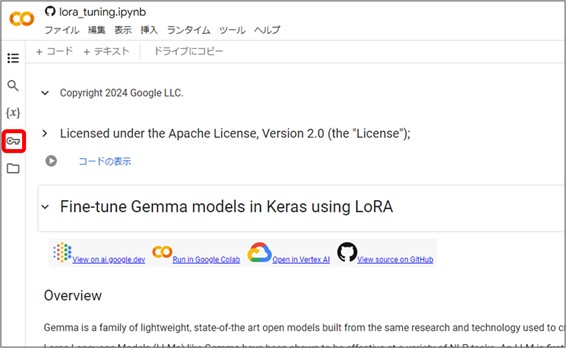
Colab内の鍵マーク『シークレット』をクリックすると、下図のような画面が表示されます。
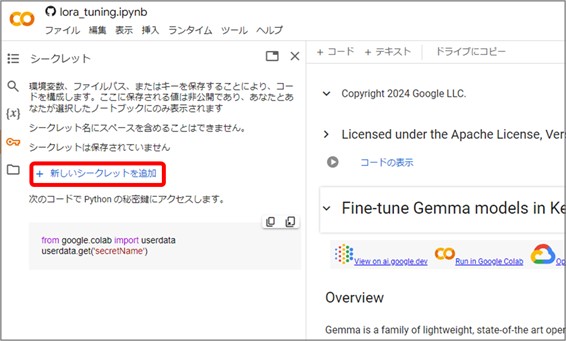
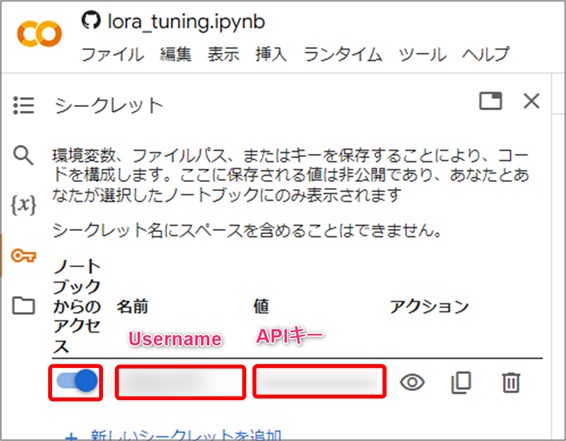
ここで『+新しいシークレットを追加』を選択し、名前にユーザーネーム、値にAPIキーを入力して、『ノートブックからのアクセス』をONにしたら、初期設定は完了です。
生成AIにPythonのコーディングをしてもらうには、画面上『+コード』から新規のコード作成を実行します。
すると、『コーディングを開始するか、AIで生成します』というテキストが表示されます。

通常はこのままこの枠にPythonのコードを入力するのですが、ここで生成AIを利用してコーディングしてみます。
テキストボックス内の『AIで生成します』をクリックし、そこに日本語でテキストを入力すると、次のようにプログラムが生成されました。
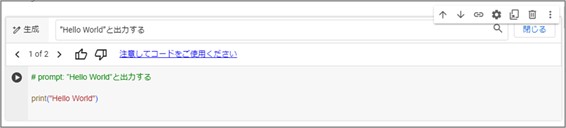
生成AIによるコーディングはまだ不完全な場合も少なくないため、コードの妥当性や、実際にPythonで実行した際の安全性、コードの著作権などについては、適切な知識を持って使用を判断する必要があります。
また、生成AIを利用したコーディングについては、無料で使用できる期間が定められており、使い続けるのであれば月額1,179円~の有料登録が必要です。
Colabの具体的な使い方については、下記URLを参照してください。
Colabの使い方
GemmaとGeminiの違いは
GemmaとGeminiは異なる生成AIプログラムですが、同じ技術のLLMを使用して開発されています。
この2種の違いについて、簡単に解説します。
| Gemma | Gemini | |
|---|---|---|
| 開発元 | ||
| モデル | 公開 | 非公開 |
| パラメータ数 | 20億/70億 | 100億/6000億/1.6兆 |
| 商用利用 | 可能(有料) | 不可能 |
GeminiはGemmaに比べて情報学習量が多く、より高度な言語タスクや画像処理などに対応しています。
GemmaはGeminiよりも情報学習量が少ない分、データ容量が少なく済んでいるだけでなく、性能としても他のオープンモデルAIに引けを取らないものを有していると公表されています。
また、容量が少ないためノートPCやGoogle Cloud上などでも利用できるというメリットがあります。
Googleの各種サービスと連携しつつ生成AIを利用できるのがGemini、開発者が生成AIをカスタマイズするためのオープンソースとして公開されているのがGemmaと考えるといいでしょう。
一般的なユーザーがテキスト生成AIを使うだけであれば、Geminiのほうが性能も良く、より自然な日本語での応答が期待できます。
自社で生成AIを利用したシステムを構築したい場合や、独自に生成AIを組み上げたい 人には、Gemmaの活用が理想です。
Gemmaを活用できること
Gemmaは「全ての組織に対して、責任ある商業利用および配布を許可する」としています。
利用規約と使用禁止ポリシーの許諾が必要ですが、これを守っていれば自由にテキスト生成AIを開発・利用できます。
使用禁止ポリシーでは、以下のようなコンテンツを、Gemmaのソースを利用して自身で生成したり、第三者に生成させたりしてはいけないと定められています。
- 著作権をはじめとした、個人や団体の権利を侵害するようなコンテンツの生成
- 違法行為や法律違反となる行為、それらを促進する表現の生成
(児童の性的虐待に関するコンテンツ、売買が禁止される違法な物質・商品・サービス等、犯罪の推奨、暴力的な表現など) - 法律・医療・会計・金融等、免許が必要となる専門職の業務に関する内容の生成
- スパム、詐欺、フィッシング、マルウェアなど生成
- 特定の個人やグループに対する危害を意図したコンテンツの生成
- 意図的な誤情報、不誠実な情報の生成
(特定個人になりすますコンテンツの生成、投資情報を生成するなど特定の人物が不正な利益を得るための誤情報の生成など) - 性的嗜好を満足させるためのポルノコンテンツの生成
(学術・芸術的価値が認められるものについてはその限りではない)
また、商用利用に際しては生成する文字量に合わせた有料プランへの加入が必須です。
利用できるGemmaの種類
Gemmaは、
- Gemma2B事前学習済みモデル
- Gemma2Bインストラクションチューニング済モデル
- Gemma7B事前学習済みモデル
- Gemma7Bインストラクションチューニング済モデル
の4種類がリリースされています。
2Bと7Bの違いはデータ処理能力の差で、2Bが20億パラメータ、7Bが70億パラメータをそれぞれ指しています。
事前学習済みモデルは、大規模なデータから生成AIに必要な単語の抽出や文章の構成方法などを学習させたモデルを指します。
インストラクションチューニングモデルは、事前学習済みモデルにさらに手を加え、ユーザーから与えられる特定の情報に対して適切な返答ができるように調整されたモデルです。
それぞれ、ユーザーの目的に合わせたモデルを利用できます。
対外用のオープンAIモデル制作
例えば、チャットボットはBtoCサイトで多く見られるサービスです。
従来、顧客の疑問を、簡単ないくつかの質問によって切り分けてチェックし、それぞれの疑問に回答するFAQページへ誘導するケースが多く見られました。
しかし、この方式では、本当に顧客が疑問に思っていることが解決できないケースが散見されました。
Gemmaを利用して追加で学習させれば、Hugging Chatのようなチャットボットの設計、開発が可能です。
対話型のテキスト生成AIによって疑問を解決に導けるため、これまでよりもストレスフリーに問い合わせ対応ができるでしょう。
社内用などのクローズドなAIモデル制作
チャットボットは社内でも活用できます。
それ以外にも、データ分析や議事録の要約、商品ページの文章作成と言った、従来は人の手を介さなければ難しかったものを、一定以上の品質で制作します。
もちろん、テキスト生成AIの技術は部分的に不完全であり、言葉がおかしかったり、誤った情報を記述したりといったケースがあるため、目視によるチェックは不可欠です。
また、社内に限定した使用用途であっても商用利用と判断される可能性が高いため、商用プランへの加入は忘れずに行いましょう。
こうした自動生成AIで対応可能な部分について、業務効率化が期待できます。

Gemmaがオープンモデルになった意味は大きい
これまで、Googleは開発したAIに関する情報を公開してきませんでした。
方針転換の根底にどのような企業判断があったのかは明らかにはされていません。
しかし、これによりテキスト生成AIの開発競争加速に繋がるほか、それぞれが独自にアレンジした生成AIとユーザーが協調することで、業務効率の改善を目指せるようになるかもしれません。
まだ不完全な技術も多いテキスト生成AIですが、今後の発展がますます期待されます。
Gemma: Introducing new state-of-the-art open models|Google
GemmaがGoogle Cloudで利用可能に|Google Cloud
Google AI for Developers|Google
Gemma Prohibited Use Policy|Google
Google、商用利用可能な軽量オープンAIモデル「Gemma」を公開|@IT
グーグルが最新AIモデルGemmaを「オープンモデル」で公開した背景|Forbes Japan
グーグル、軽量でオープンな新AIモデル「Gemma」|Impress Watch
Googleから新AI「Gemma」、商用利用OKのオープンモデル|ケータイWatch
大規模言語モデル(LLM)とは? 仕組みや種類・用途など|日立ソリューソンズ・クリエイト
【AIML】事前学習モデル(pre-trained models)と転移学習(transfer learning)って知っていますか?|TechHarmony
【Googleの最先端AIモデル】Gemmaとは?Geminiとの違いも解説|AI相談.com
Instruction Tuningにより対話性能を向上させた3.6B日本語言語モデルを公開します|LINE Engineering
HuggingChatとは何か?ChatGPTとの比較でわかるオープンソース生成AIの驚きの性能|ビジネス+IT
