Facebookが公開したfastTextのインストールと使用方法について解説

(2019年9月13日更新:FastTextのパラメータ紹介に誤りがあるとの指摘を受けて再調査し修正いたしました。勘違いによりご迷惑をおかけしたことをお詫びいたします。)
- 誤:これより少ない出現割合の単語は無視します
- 正:この値より高出現率の単語は、その単語の出現率から計算された確率値に従って無視されます
こんにちは。エンジニアのMです。
ここでは、自然言語処理ライブラリ「fastText」の使用方法について解説していきます。
理論については他で丁寧に解説されているので、使用方法について重点的に解説していきたいと思います。
fastTextとは?
Facebook社が2016年8月18日に公開した自然言語処理ライブラリです。
Google社が発表した「Word2Vec」の分散ベクトル表現というアイデアを基に改良したものです。
fastTextは、単語をsubword(部分語)に分解したものを学習に組み込んでいることが最大のポイントです。
これにより、原形(例:Go)と活用形(例:Going)のような共通の部分を持つ語句について、その関係性をうまく学習します。
さらに学習が非常に高速で、短時間の学習で高精度なモデルを学習します。
| Yahoo | Amazon full | Amazon polarity | ||||
|---|---|---|---|---|---|---|
| 適合率 | 時間 | 適合率 | 時間 | 適合率 | 時間 | |
| char-CNN | 71.2% | 1日 | 59.5% | 5日 | 94.5% | 5日 |
| VDCNN | 73.4% | 2時間 | 63.0% | 7時間 | 95.7% | 7時間 |
| fastText | 72.3% | 5秒 | 60.2% | 9秒 | 94.6% | 10秒 |
比較対象が非常に計算の重いディープラーニングベースの手法ですが、これらと遜色ない精度を秒単位の計算時間で実現しています。
しかしfastTextにも、日本語のカタカナ語に弱いという弱点があります。
- fastTextのsubword(部分語)の弊害 – studylog/北の雲 [外部リンク]
これについても後で確認してみたいと思います。
Windows 10でLinux環境のインストール
今回はWindows 10の機能「Windows Subsystem for Linux」(WSL)を使って、Windows上にLinux環境を構築していきたいと思います。
WSLなら簡単にLinux環境を作ることができ、試すだけ試したら環境をすぐに削除することもできます。
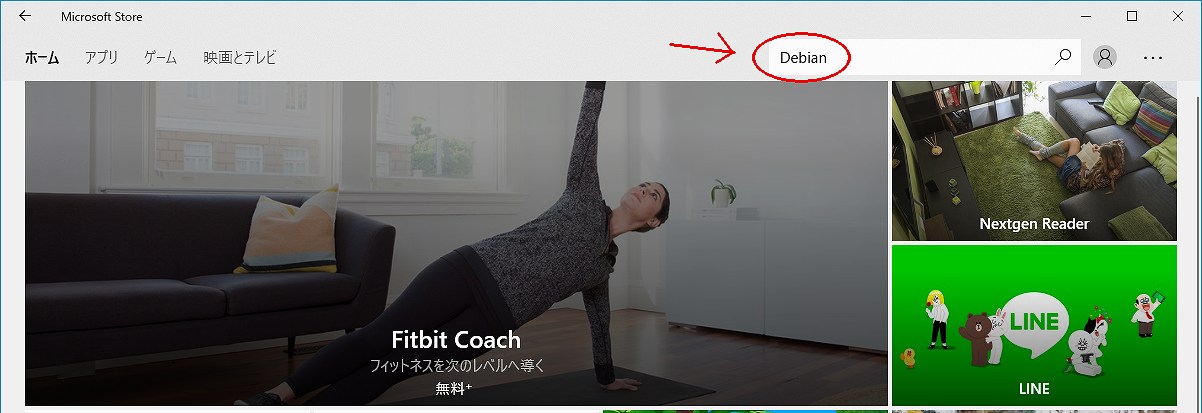
まずはタスクバーから「Microsoft Store」を開いて、右上の検索バーから「Debian」を検索します。

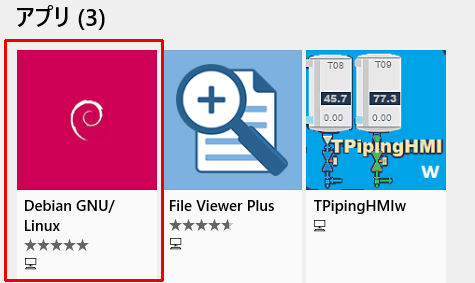
アプリに「Debian GNU/Linux」が見つかるのでクリックし、アプリ詳細のページから「インストール」します。
インストールできない場合は、Windows 10のバージョンが古いと思われるので最新のアップデートを適用してください。
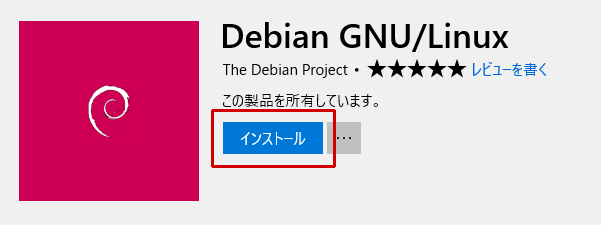
インストールが完了したら、「スタートにピン留め」しておきましょう。
これでDebianを起動する準備ができました。
WSLの初回起動
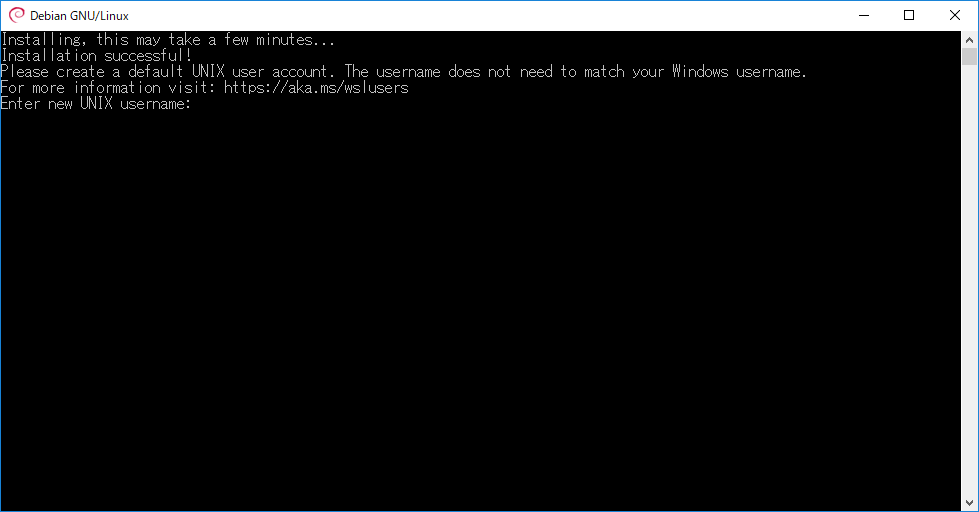
初回起動時はこのような画面が表示され、ユーザー名とパスワードの入力を求められます。
Windowsのユーザー名と一致する必要はないと表示されますが、パスワードまで含めて揃えてしまったほうが覚えやすくて良いかもしれません。
今後の操作もこのテキストベースの画面(CUI:キャラクタユーザインタフェース)上で行うことになります。
最低限操作に必要なコマンドについては、適宜示しつつ進めていきたいと思います。
なお、パスワード入力では「・」や「*」が表示されませんが、CUIではこの仕様が一般的です。
fastText導入の下準備
Debianでは、パッケージマネージャ「APT(Advanced Package Tool)」を使ってソフトウェアの管理を行います。
まずはリポジトリ(ソフトウェア情報の一覧)を更新して、インストール済みのパッケージを最新版にしましょう。
CUIに表示された、
(ユーザ名)@(コンピュータ名):~$
を「プロンプト」と言います。これに続けてコマンドを入力することで、様々な操作を行います。
「$」の前の「~(チルダ)」はホームディレクトリを意味します。
$ sudo apt update
(「sudo」のためにパスワードを求められるので入力)
$ sudo apt upgrade
(継続確認を求めてくるので、「y」を入力してEnter)
「sudo」はWindowsで言う「管理者として実行」です。「apt update」を管理者権限で実行するという意味となります。
「Permission denied(アクセス拒否)」というエラーが出る場合は、「sudo」を忘れていることがほとんどです。
sudoの初回実行時はパスワードの入力を求められるので、先程設定したパスワードを入力する必要があります。
「apt update」でソフトウェアのパッケージ情報を最新にして、「apt upgrade」でパッケージを更新します。
ここからは必要なソフトのインストール作業です。
fastTextは「GitHub」で公開されているので、「Git」を使って最新のものを取得する必要があります。
まずは「Git」をインストールします。
$ sudo apt -y install git
「-y」オプションを使うことで、先程の継続確認をスキップできます。
またfastTextは分かち書き(単語毎で文章を区切ること)された文章を入力として実行するので、日本語の分かち書きされたテキストファイルが必要です。
さらに後に学習モデルを使って類語検索を実行するために、プログラミング言語「Python」と必要なライブラリもインストールします。
$ sudo apt -y install python3
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
$ sudo pip install gensim
「wget」コマンドでPythonのパッケージ管理ツール「pip」をインストールするためのファイルを取得し、「sudo python3 get-pip.py」でインストールしています。
今インストールしたpipを使って自然言語処理ライブラリ「Gensim」をインストールします。
「Gensim」はPython用の自然言語処理ライブラリで、最近のバージョンではfastTextも実行できるようになりました。
ここでは類似の単語を出力させるためだけに使いますが、実際は高機能なライブラリで、トピックモデルの作成、tf-idf、Word2Vecなど自然言語処理関係なら大抵のことができます。
さらに「fastText」をインストールするために必要な「make」と、コードのコンパイルに必要な「gcc」と「g++」もインストールしておきます。
$ sudo apt -y install make gcc g++
以下のコマンドでバージョン情報が表示されれば、問題なくインストールされていることが確認できます。
$ git --version
git version 2.11.0
$ python3 -V
Python 3.5.3
$ make -v
GNU Make 4.1
Built for x86_64-pc-linux-gnu
Copyright (C) 1988-2014 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/6/lto-wrapper
Target: x86_64-linux-gnu
(中略)
gcc version 6.3.0 20170516 (Debian 6.3.0-18+deb9u1)
$ g++ -v
Using built-in specs.
COLLECT_GCC=g++
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/6/lto-wrapper
Target: x86_64-linux-gnu
(中略)
gcc version 6.3.0 20170516 (Debian 6.3.0-18+deb9u1)
$ pip list
Package Version
--------------- ---------
boto 2.48.0
boto3 1.7.25
botocore 1.10.25
bz2file 0.98
certifi 2018.4.16
chardet 3.0.4
docutils 0.14
gensim 3.4.0
idna 2.6
jmespath 0.9.3
numpy 1.14.3
pip 10.0.1
python-dateutil 2.7.3
requests 2.18.4
s3transfer 0.1.13
scipy 1.1.0
setuptools 39.2.0
six 1.11.0
smart-open 1.5.7
urllib3 1.22
wheel 0.31.1
リポジトリの都合で最新版ではないソフトウェアもありますが、支障はありません。
fastTextの導入
Gitを使ってfastTextの最新版を入手し、コンパイルします。
~$ git clone https://github.com/facebookresearch/fastText.git
~$ cd fasttext
~/fasttext$ make
「cd」はチェンジディレクトリを意味し、これはWindowsでも同じコマンドが使えます。
上で示したように、「git clone」で生成されたディレクトリに移動したので「~/fasttext$」と表記が変わります。
「make」でfastText実行ファイルの生成が始まります。
これでようやくfastTextの準備ができました。
コマンドラインでの操作は慣れないと大変ですが、Windowsの「コマンドプロンプト」での操作にも通ずるので、慣れておくと何かと便利です。
分かち書きした日本語のテキストを用意する
分かち書きの済んでいるデータを用意して、fastTextを実行してみましょう。
このコマンドでデータをダウンロードします。
$ wget https://s3-ap-northeast-1.amazonaws.com/dev.tech-sketch.jp/chakki/public/ja.text8.zip
このデータに関する説明はこちらから参照してください。
- 日本語版text8コーパスを作って分散表現を学習する – 自然言語処理の深遠 [外部リンク]
こういったデータセットはたくさん公開されていますが、日本語のものはそれほど多くありません。
作成者の方に感謝しつつ、早速試していきたいと思います。
zip形式の圧縮ファイルをダウンロードしましたが、これを展開する手段を用意していませんでした。
「unzip」を使いましょう。
$ sudo apt -y install unzip
インストールに成功したら、以下のコマンドで圧縮ファイルを展開します。
$ unzip ja.text8.zip
展開されたファイルを確認してみましょう。
$ ls
args.o fasttext.o PATENTS setup.cfg
classification-example.sh get-wikimedia.sh pretrained-vectors.md setup.py
classification-results.sh ja.text8 productquantizer.o src
CMakeLists.txt ja.text8.zip python tests
CONTRIBUTING.md LICENSE qmatrix.o utils.o
dictionary.o Makefile quantization-example.sh vector.o
docs MANIFEST.in README.md website
eval.py matrix.o runtests.py wikifil.pl
fasttext model.o scripts word-vector-example.sh
ダウンロードした「ja.text8.zip」と並んで、展開後の「ja.text8」があるはずです。
「ls」はWindowsの「dir」にあたるコマンドで、カレントディレクトリのファイルを一覧で表示するコマンドです。
Linuxでは、基本的に「cd」と「ls」を使ってファイルを辿っていくことになります。
fastTextを試してみる
この「ja.text8」に対してfastTextを実行してみましょう。
$ ./fasttext skipgram -input ja.text8 -output ja.text8.model
1分ほど待つと、学習済みのモデルが出力されます。
$ ls
args.o get-wikimedia.sh PATENTS setup.py
classification-example.sh ja.text8 pretrained-vectors.md src
classification-results.sh ja.text8.model.bin productquantizer.o tests
CMakeLists.txt ja.text8.model.vec python utils.o
CONTRIBUTING.md ja.text8.zip qmatrix.o vector.o
dictionary.o LICENSE quantization-example.sh website
docs Makefile README.md wikifil.pl
eval.py MANIFEST.in runtests.py word-vector-example.sh
fasttext matrix.o scripts
fasttext.o model.o setup.cfg
binファイルは「subword」などの学習に使ったデータを含んだ大きなバイナリデータで、vecファイルは単語ベクトルのデータを含むテキストファイルです。
vecファイルの中を覗いてみると、
$ less -S ja.text8.model.vec
75207 100
( 0.14815 3.125e-05 -0.11554 -0.17903 -0.099862 0.40963 -0.17575 -0.30447 0.015418 0.07217 -0.14087 -0.019106 -0.21111 -0
.
) 0.066231 0.033538 -0.1073 -0.26016 -0.12875 0.38485 -0.1054 -0.23548 0.0096073 0.038102 -0.12906 -0.055455 -0.16001 -0.
1
れ 0.21685 0.044871 0.35449 -0.35287 0.31105 0.29117 0.017137 -0.48615 -0.1716 0.17481 0.080287 0.30571 -0.071116 0.020115
さ 0.32312 0.10182 0.25626 -0.40267 0.27188 0.21636 0.0010242 -0.44353 -0.16135 0.14666 0.10148 0.20979 -0.011649 -0.07434
5
ある 0.17216 0.062272 0.19768 -0.13805 0.22405 0.36243 0.12666 0.11615 -0.020773 -0.1361 -0.079868 0.0072632 -0.17295 0.01
88
いる 0.20193 -0.19419 0.25827 -0.04983 0.099089 0.47881 -0.052818 -0.11636 -0.053413 0.10218 -0.067288 0.31957 -0.03978 -0
.0
する 0.21552 0.091436 0.43869 -0.31472 0.16137 0.40015 0.06602 0.080579 -0.13487 -0.07759 0.078949 0.13573 0.015429 -0.102
88
・ -0.20521 0.2153 -0.081267 -0.63096 0.20645 0.261 -0.3186 -0.010709 -0.092999 0.31204 -0.12115 -0.027166 -0.26334 0.0140
(以下略)
このようになっています。
「less」コマンドで内容を表示してみました。終了するには「q」を入力してください。
「-S」オプションは「折り返さずに表示」です。一行が非常に長いので、見やすくするために使用しています。
各行に単語と、100次元ベクトルの各成分値が並んでおり、一行目には辞書の単語数と次元数が示されています。
次はこの単語ベクトルの値を使って、類似の単語について出力してみます。
検証用に新しいPythonライブラリを導入し、Pythonインタプリタを起動します。
$ sudo pip install gensim
$ python3
予めインストールしておいたライブラリ「Gensim」を使って類語検索をしてみましょう。
以下に従ってPythonのコードを入力してください。
ここまで同じ作業を行っていれば、一行毎のコピー&ペーストで動作するはずです。
(コピーしやすいようにここでは起動時の文と、行頭の「>>> 」は省略しています)
(命令)
from gensim.models import KeyedVectors
word_vecs = KeyedVectors.load_word2vec_format('~/fastText/ja.text8.model.vec', binary=False)
word_vecs.wv.most_similar(positive=['公園'])
(結果)
[('森林公園', 0.8020797371864319), ('東公園', 0.7740828394889832), ('西公園', 0.7673497200012207), ('緑地公園', 0.7521510720252991), ('開園', 0.7321162223815918), ('レクリエーション', 0.7305341362953186), ('せせらぎ', 0.730256974697113), ('海浜', 0.7274555563926697), ('園内', 0.7228965759277344), ('緑地', 0.7226329445838928)]
positiveで指定した単語の類語が表示できました。
fastTextの結果は毎回変わるので、必ずしもこの通りになるとは限りません。
有名な 「国王」-「男」+「女」=? という演算もしてみましょう。
Pythonインタプリタに続けて以下を入力します。
(命令)
word_vecs.wv.most_similar(positive=['国王', '女'], negative=['男'])
(結果)
[('フレゼリク', 0.6514100432395935), ('サヴォイア', 0.6494227051734924), ('ヴァロワ', 0.6466787457466125), ('女王', 0.6462998986244202), ('ナバラ', 0.6462284326553345), ('王妃', 0.6452188491821289), ('世', 0.6447607278823853), ('ヴァーサ', 0.6437854766845703), ('アフォンソ', 0.6433125734329224), ('君主', 0.6432636976242065)]
今回の例では女王は一番上には来ませんでした、残念。皆さんの環境ではどうなったでしょうか。
fastTextの学習次第で結果は変わります。
ちなみにPythonインタプリタやWindowsコマンドプロンプト、Linuxのターミナルでは、カーソルキーの上下で過去のコマンドを参照できます。活用してください。

せっかくなので、一つ追加で実験してみました。
>>> word_vecs.wv.most_similar(positive=['駅'], negative=[])
[('総武本線', 0.8379458785057068), ('東上本線', 0.8265190720558167), ('関西本線', 0.8241926431655884), ('本線', 0.8198679685592651), ('南海本線', 0.8160605430603027), ('東京貨物ターミナル', 0.8137922883033752), ('終着駅', 0.8106522560119629), ('中央本線', 0.809557318687439), ('緩行', 0.807392418384552), ('東田本線', 0.8063435554504395)]
>>> word_vecs.wv.most_similar(positive=['駅'], negative=['電車'])
[('南口', 0.4031747579574585), ('東口', 0.38484054803848267), ('跨線橋', 0.36691364645957947), ('東側', 0.36269569396972656), ('南端', 0.3622940480709076), ('南側', 0.3613092303276062), ('入江', 0.35677608847618103), ('西端', 0.3528499901294708), ('柏', 0.3511129319667816), ('入口', 0.3501090407371521)]
「駅」で検索すると、電車の路線名がずらっと並びました。
そこで、「駅」-「電車」としたのが2番目の結果です。
電車成分が無くなって、鉄道駅そのものに関する単語が出力されました。
さらに「バス」をpositive側に追加してみます。
>>> word_vecs.wv.most_similar(positive=['駅','バス'], negative=['電車'])
[('停留所', 0.7213354110717773), ('発着', 0.6941797733306885), ('バスターミナル', 0.6911329627037048), ('駅前', 0.6766102313995361), ('バス停', 0.6750752329826355), ('最寄り', 0.6722031235694885), ('南口', 0.6617298722267151), ('乗り場', 0.6588212847709656), ('阪急バス', 0.6387990117073059), ('東口', 0.6316502690315247)]
駅とバスに関係のある単語なので、「駅前」は納得です。
「バスターミナル」も、主に駅に併設されているものなので納得がいきます。
このあたりはWord2Vecと変わらず、興味深い結果が出て面白いところです。
冒頭で、fastTextはカタカナ語に弱いという話がありました。
これについても確認してみましょう。
>>> word_vecs.wv.most_similar(positive=['ティッシュ'])
[('ディッシュ', 0.8413184881210327), ('レーティッシュ', 0.7607399225234985), ('ブリティッシュコロンビア', 0.7457284331321716), ('ブリティッシュ・ブルドッグス', 0.745701253414154), ('ベルベット', 0.7148540616035461), ('キュラソー', 0.6999078989028931), ('チェリッシュ', 0.6994593143463135), ('イディッシュ', 0.699065625667572), ('ジート', 0.6825165152549744), ('カバナ', 0.6767375469207764)]
「ディッシュ」と「ティッシュ」は字面が似ているだけで、全然関係なさそうですね。
小規模なデータでの学習モデルですが、fastTextの弱点について確認ができました。
fastTextのパラメータを調整する
fastTextにおいて、各学習パラメータの設定は重要です。
- エンジニアMのAI学習記録(2018年3月分) | フォームズのブログ [リンク]
次元数やEpoch(学習回数)を変えるだけでだいぶ結果が変わります。
先程のデータについて、少しパラメータを変えて学習させてみましょう。
$ ./fasttext skipgram -input ja.text8 -output ja.text8.model200 -dim 200 -epoch 25
「-dim」で単語ベクトルの次元数を指定(デフォルトは「100」)し、「-epoch」で学習回数を指定(デフォルトは「5」)します。
回数と次元を増やしたので、今回は10分ほどかかります。
パラメータについては、fastText公式に一覧があります。
- List of options · fastText [リンク]
この中でよく使うと思われるオプションについて簡単にまとめておきます。
| -minCount | これより少ない出現回数の単語は無視します |
|---|---|
| -t | この値より高出現率の単語は、その単語の出現率から計算された確率値に従って無視されます(出現する度に判定する) |
| -lr | 大きいほど学習が早く進みますが、結果が不安定になることがあります |
| -dim | 単語ベクトルの次元数です。100~300が推奨されています |
| -epoch | 学習回数です。多すぎても過学習するので、適当な設定が必要です |
| -thread | 学習に使うスレッド数です。CPUのスレッド数に応じて設定します |
| -pretrainedVectors | 学習済みベクトルを指定します(例:Wikipediaの学習済みモデル) |
さて、新たに作ったモデルを使って先程と同じことをしてみましょう。
$ python3
(コピーしやすいようにここでは起動時の文と、行頭の「>>> 」は省略しています)
(命令)
from gensim.models import KeyedVectors
word_vecs = KeyedVectors.load_word2vec_format('~/fastText/ja.text8.model200.vec', binary=False)
sim = word_vecs.wv.most_similar
sim(positive=['公園'])
(結果)
[('こうえん', 0.5978502035140991), ('遊歩道', 0.5889005064964294), ('園地', 0.5833567380905151), ('緑地', 0.5770828127861023), ('史跡', 0.5745777487754822), ('霞ヶ丘', 0.5719053149223328), ('森林公園', 0.5699493288993835), ('花瀬', 0.5644041299819946), ('東公園', 0.5635347962379456), ('開園', 0.5567662119865417)]
コードはほぼ一緒ですが、読み込むファイルが先程作った「~/fastText/ja.text8.model200.vec」に変わっています。
また、「sim()」だけで類語検索を実行できるようにコードを変更しました。少し見た目がすっきりしたかと思います。
パラメータを変えて学習させたので、結果が前回とかなり異なっています。
>>> sim(positive=['国王','女'], negative=['男'])
[('王', 0.5322331786155701), ('王妃', 0.47905752062797546), ('エルジュビェタ', 0.4750189781188965), ('マヘンドラ', 0.47424349188804626), ('ウィレム', 0.4709622263908386), ('エマヌエーレ・フィリベルト', 0.4707062542438507), ('女王', 0.47042036056518555), ('フェリペ', 0.4700654149055481), ('アフォンソ', 0.46844780445098877), ('世', 0.46831536293029785)]
新しいモデルでは、例の「国王」-「男」+「女」=?という演算は「女王」が少し遠くなってしまいました。
これはパラメータ設定があまり良くなかったのかもしれません。
いかがでしたか?
Debianのインストールから、Gensimを使った類語検索までの流れについて解説しました。
LinuxとCUIの両方に慣れていない方、Pythonを触ったことのない方はコピー&ペーストで精一杯だったかもしれませんが、雰囲気はつかめたかと思います。
ぜひ他にも色々と試してみてください。
